An Overview On Regularization
In this article we will discuss about the need of regularization and its different types.
In supervised machine learning models we will train our model on data called training data.Our model will learn from this data. In some cases our model will learn from data patters along with noises in training data.In such cases our model will have a high variance and our model will be overfitted. Such an overfitted model will have less generalization.That means they will perform well in training data but will not perform good with new data. Goal of our machine learning algorithm is to learn the data patterns and ignore the noise in the data set.
Now, there are few ways we can avoid overfitting our model on training data like cross-validation , feature reduction, regularization etc.In this article we will discuss about regularization.
Regularization basically adds the penalty as model complexity increases. Regularization parameter (lambda) penalizes all the parameters except intercept so that model generalizes the data and won’t overfit.
Let us understand how penalizing loss function helps to avoid overfitting
We will explain about regularization by taking the case of linear regression. The cost function for linear regression is

Our goal is to minimize cost function J( θ0, θ1).

Let our hypothesis be as follows

The idea is that we want to eliminate the influence of parameters like θ2, θ3, θ4 etc without actually getting rid of these features or changing the form of our hypothesis, we can instead modify our cost function. Here let us modify the influence of θ3 and θ4.

We’ve added two extra terms at the end to inflate the cost of θ3 and θ4. Now, in order for the cost function to get close to zero, we will have to reduce the values of θ3 and θ4 to near zero. This will in turn greatly reduce the values of θ3x3³ and θ4x4⁴ in our hypothesis function.

That means for smaller values of parameters like θ3, θ4 hypothesis will be simpler and model will be less prone to overfitting.
Consider a case with large number of features(x1,x2,x3….x100).Then we will have large number of parameters(θ1,θ2……θ100).In this case we can do the same by using regularization. For that we will add a new regularization term to our cost function.

here λ is the regularization parameter. Here we have to minimize J(θ). As the value regularization parameter increases it reduces the value of coefficients and thus reducing variance without losing important properties in the data.
What if we choose higher value of λ ?
For higher value of λ , algorithm even fails to fit training data and result in underfitting. Also gradient descent will fail to converge.Parameters like θ1,θ2…θn becomes close to zero.Then

How to choose right value of λ ?
It will be between 0 and a large value. We need to find an optimal value of λ so that the generalization error is small.We can use methods like k-fold cross validation for that.
Types Of Regularization
There are mainly two types of regularization.
- L1 regularization (Lasso regularization)
- L2 regularization(Ridge regularization)
L1 Regularization(Lasso Regression)
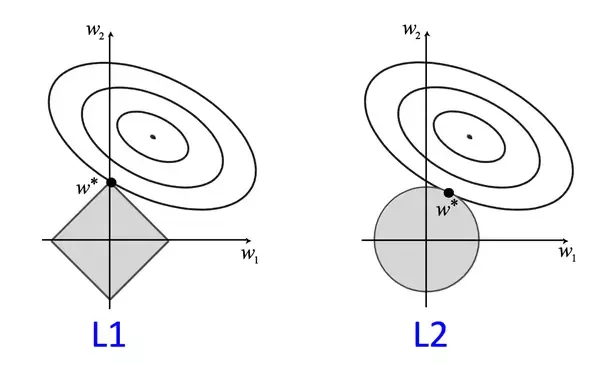
L1 regularization adds an L1 penalty equal to the absolute value of the magnitude of coefficients.When our input features have weights closer to zero this leads to sparse L1 norm. In Sparse solution majority of the input features have zero weights and very few features have non zero weights.

Features:
- L1 penalizes sum of absolute value of weights.
- L1 has a sparse solution
- L1 generates model that are simple and interpretable but cannot learn complex patterns
- L1 is robust to outliers
L2 Regularization(Ridge regularization)
L2 regularization is similar to L1 regularization.But it adds squared magnitude of coefficient as penalty term to the loss function. L2 will not yield sparse models and all coefficients are shrunk by the same factor (none are eliminated like L1 regression)

Features:
- L2 regularization penalizes sum of square weights.
- L2 has a non sparse solution
- L2 regularization is able to learn complex data patterns
- L2 has no feature selection
- L2 is not robust to outliers
The key difference between these techniques is that L1 regression shrinks the less important feature’s coefficient to zero thus, removing some feature altogether while L2 regression reduces it to close to zero. So, L1 regression works well for feature selection in case we have a huge number of features.
References:
- Machine Learning Course — Andrew Y Ng
